
 Abonnements
Abonnements
13 Januar 2017 |
La Revue POLYTECHNIQUE
Après le «cloud computing», voici le «fog computing»
Edouard Huguelet
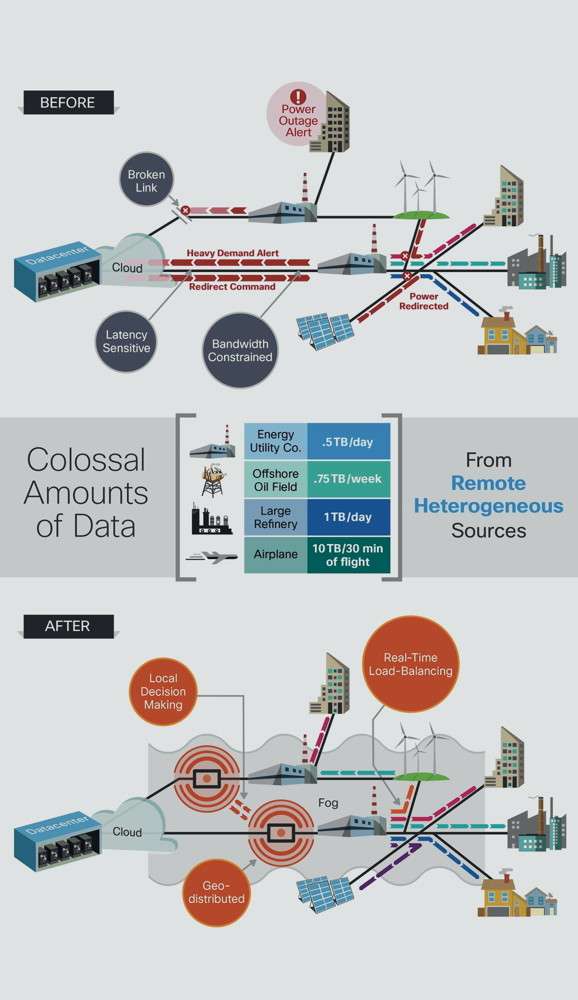
Dans le domaine informatique, avec le volume croissant des banques de données et leurs masses d’archivage, le «cloud computing» (données hébergées à l’externe) s’impose de plus en plus. Mais voici qu’apparaît le «fog computing» (données géo-distribuées), qui convient particulièrement à l’Internet des objets (IoT).
Un organisme appelé «OpenFog Consortium» a été créé en décembre 2015 par cinq ténors de l’informatique, à savoir: ARM, Cisco, Dell, Intel, Microsoft et une université, en l’occurrence celle de Princeton (New Jersey). À cette équipe sont venus s’ajouter des experts de l’Institut des ingénieurs électriciens et électroniciens (IEEE), de Schneider Electric et de GE Digital (une entité qui regroupe toutes les activités numériques de General Electric), l’objectif étant d’appliquer la nouvelle vision informatique appelée «fog computing» à l’IoT (Internet of Things - Internet des objets). Au fait, le mot «fog» est assez amusant: en français, cela signifie «brouillard». En d’autres termes, on imagine donc quelque chose d’insaisissable, mais néanmoins omniprésent. Cette approche ressemble beaucoup à celle du «World Wide Web» (www) avec son protocole http qui a littéralement fait exploser l’Internet au début des années 1990.


Des systèmes moins vulnérables
Avec l’informatique hébergée (cloud), le stockage et l’archivage des données sont externalisés, ce qui libère certes la majeure partie de l’espace local de stockage des données (le disque dur, par exemple), mais génère en revanche un intense trafic via Internet. Pour ce qui est des données géo-distribuées (fog), celles-ci sont réparties soit directement sur les objets dits «intelligents», ou alors dans des passerelles implantées à proximité immédiate de ces derniers, constituant en quelque sorte des micro-réseaux répartis. Les systèmes sont, de la sorte, beaucoup moins vulnérables.
Imaginez le risque de panne, de dommages ou de piratage au centre d’hébergement externalisé qui stocke vos données. En cas de panne, avec un objet IoT basé sur le«fog computing», les dégâts sont limités et de toute façon localisés. Chacun ici en Suisse garde en mémoire la panne géante du serveur de Credit Suisse en janvier 2014 et celle, plus récente, ayant pour source une panne de serveur chez Swisscom. Ou encore l’endommagement en 2012 de plusieurs importants centres de données «cloud» à New-York et au New Jersey, provoqué par l’ouragan Sandy. La simple pensée d’une intrusion malveillante dans ces serveurs géants donne la chair de poule.

|
Comparaison entre le «cloud» et le «fog».
|
Au carrefour des automatismes et de l’informatique distribuée
L’approche «fog» s’inscrit décisivement dans l’environnement des automatismes basés sur des réseaux de terrain, ce qu’a bien sûr parfaitement compris, entre autres, le français Schneider Electric, actif de longue date dans ce domaine. C’est l’opinion de Pascal Brosset, responsable de l’activité dite «Stratégie et technologie» de Schneider Electric Global Solutions, qui affirme: «En rejoignant l’OpenFog Consortium, nous renforçons notre engagement dans le développement et l’adoption de standards en la matière, une implication qui s’aligne sur notre volonté d’intégrer au plus tôt des standards de réseaux ouverts dans nos architectures d’automatismes et d’assurer une intégration plus étroite entre les systèmes d’information d’entreprises et les infrastructures opérationnelles, que promet l’Internet des objets industriels».
Autre ralliement important au conseil d’administration de l’OpenFog Consortium, celui de l’IEEE, la plus importante association professionnelle au monde pour la filière de l’électricité, de l’informatique et de l’électronique, comptant plus de 400’000 membres. Elle a été fondée en 1963 par la fusion du vénérable AIEE (American Institute of Electrical Engineers) et du non moins vénérable IRE (Institute of Radio Engineers) tous deux créés en 1912 (Thomas Edison était encore dans la force de l’âge et y a joué un rôle actif!). L’association possède de nombreux comités, édite des normes et des publications, organise des conférences. Donc le ralliement de l’IEEE est un important gage pour la promotion et la standardisation de l’OpenFog (que certains de ses détracteurs appellent «Open Frog»). Trève de commentaires!
D’autres ralliements
Outre les membres fondateurs précités, l’OpenFog Consortium compte désormais dix-sept sociétés, laboratoires et universités dans ses rangs, dont FogHorn Systems (développeur de logiciels), Fujitsu, GE Digital, Marsec, Nebbiolo Technologies, PrismTech, Real-Time Innovations, Sakura Internet, Schneider Electric et Toshiba. Suite à la publication d’un livre blanc sur l’architecture OpenFog (www.openfogconsortium.org/resources/white-papers), l’alliance industrielle a mis en place plusieurs groupes de travail spécialisés, actifs sur des thèmes tels que les communications, la sécurité, les bancs d’essai, l’infrastructure logicielle, etc.

|
Un banc d’essai à Cisco Live, San Diego.
|
Une démonstration dans le cadre d’un congrès
Dans les faits, l’OpenFog Consortium compte développer un ensemble cohérent de logiciels structurels (framework) ouverts. L’association souhaite instituer un forum de discussion sur les meilleures pratiques du «fog computing», influencer les organismes de normalisation (c’est d’ailleurs déjà bien parti avec l’IEEE) et mettre en place une plate-forme d’essai à l’université de Princeton. Certes, certains défis, inhérents à l’informatique géo-distribuée sont à relever, notamment les délais de latence dans les réseaux, le support des nœuds d’extrémité mobiles, les goulets d’étranglement non prédictibles en termes de bande passante, la perte de connexion, ainsi que la coordination distribuée des systèmes et des clients. Il y a encore du pain sur la planche!
Une démonstration sous forme de banc d’essai a été suivie avec intérêt par les participants dans le cadre de la manifestation «Cisco Live» à San Diego, qui s’est tenue du 7 au 11 juin 2015 dans la métropole sud-californienne. Il s’agissait d’un cas pratique d’Intel, qui montrait les différences entre un réseau à intelligence décentralisée (fog) et un système basé sur des données hébergées (cloud). La démonstration était, selon les animateurs, «deceptively simple» (d’une simplicité «consternante»). Sous un aspect a priori relativement rustique, elle recelait toutefois de nombreuses subtilités. On y trouvait, par exemple, neuf programmes informatiques écrits en langages Python, Bash ou C++, trois nano-ordinateurs Raspberry, cinq plates-formes électroniques Arduino et trois machines virtuelles, toutes mises en réseau, utilisant MQTT (un système de messagerie TCP-IP simplifié), la modulation de largeur d’impulsion PWM et la transmission infrarouge. Les techniques physiques concernaient, par exemple, la détection, la vision, le traitement de phénomènes asynchrones et le contrôle de systèmes dits «cyber-physiques», en temps réel.
La saturation du «cloud» est inéluctable
Les innombrables transferts massifs de données échangées via le «cloud» atteignent un niveau préoccupant et l’accroissement de ce flux est quasi logarithmique. Si les objets IoT (estimés à plus de 50 milliards vers 2020) dépendaient tous de données externalisées, il est évident que la saturation des systèmes de données externalisées est programmée, non pas pour une question de capacités de stockage (ce n’est pas le silicium qui manque !), mais surtout en raison de problèmes de latence (temps perdu), de temps d’accès aux données et de bande passante (risques de saturation). D’où l’intérêt de l’intelligence et de la mémoire réparties, notamment par les solutions «fog».
Reste toutefois que le stockage externalisé reste tout de même intéressant pour le stockage massif de données d’archives, de volumineux fichiers d’images ou pour l’allégement des mémoires aux disques d’ordinateurs personnels, leurs possesseurs pouvant dès lors «voyager léger», tout en ayant néanmoins un accès permanent à des masses de données prenant beaucoup d’espace de mémoire, comme des photothèques et autres fichiers personnels, par exemple. D’autre part, les données externalisées, peuvent aussi, le cas échéant, jouer un rôle de sauvegarde redondante pour des données vitales.
Le problème principal est d’éviter l’anarchie, raison pour laquelle le fameux groupement OpenFog Consortium a été créé, non seulement pour développer et promouvoir les solutions «fog», mais aussi pour uniformiser universellement les procédures d’échanges de données, avant que l’anarchie ne s’installe.
Du côté des utilisateurs
Le «fog computing» constitue un marché relativement nouveau, mais il va croître en même temps que celui des objets connectés. On voit d’emblée émerger des applications dans des domaines tels que les véhicules automobiles, l’aviation, les transports publics, la domotique, l’énergie, le génie médical ou d’autres encore. Et l’IoT ne concerne pas que des «objets» connectés au sens limitatif du terme, mais aussi des ensembles d’objets reliés en réseau locaux, ce qui est le cas de bâtiments ou autres infrastructures composant notre environnement.
Le «fog computing» constitue un marché encore relativement nouveau, avec des possibilités encore inexplorées, mais qui sera rapidement en folle évolution: il va croître en même temps que celui, déjà beaucoup mieux connu, des objets connectés à Internet (IoT). Il va donc impliquer une facilité d’utilisation des applications dans le domaine des véhicules connectés ou du suivi médical, par exemple. Les objets ne seront d’ailleurs pas les seuls à être connectés, car il est également envisageable de connecter des bâtiments, des réseaux de distribution ou différentes infrastructures (des magasins ou des systèmes de production d’énergie, par exemple), qui composent notre environnement. Les applications sont innombrables.
De par le principe du «fog computing», les données émises par des capteurs implantés dans les objets IoT peuvent être reprises et traitées localement, et les mesures de sécurité peuvent être immédiatement engagées, ce qui constitue un élément décisif pour certaines industries critiques. D’autres objets «intelligents» peuvent embarquer un pré-traitement avancé des données issues de leurs capteurs.
Ceci dit, dans le cas de systèmes de conduite de processus de production, dans les réseaux de distribution d’énergie ou dans les transports publics, le «fog computing» permet d’appliquer des procédures de maintenance préventive, pour éviter des pannes. Ou encore, des caméras positionnées sur les parkings, au-delà de la simple vidéo-surveillance, peuvent aussi tirer parti de logiciels d’analyse géo-distribués afin de prédire le niveau d’affluence dans les rayons des supermarchés et optimiser ainsi le travail du personnel.




