
 Des abonnements
Des abonnements
Apprentissage automatique avec commande basée sur PC
Le Machine Learning (ML) est une forme d’intelligence artificielle (IA) axée sur la création de systèmes qui apprennent ou améliorent leurs performances en fonction des données qu’ils traitent. L’intelligence artificielle est un terme générique qui désigne des systèmes ou des machines simulant une forme d’intelligence humaine. Le Machine Learning (apprentissage machine) et l’IA sont souvent abordés ensemble et ces termes sont parfois utilisés de manière interchangeable, bien qu’ils ne renvoient pas exactement au même concept. Une distinction importante est que, même si l’intégralité de l’apprentissage machine repose sur l’intelligence artificielle, cette dernière ne s’y limite pas.
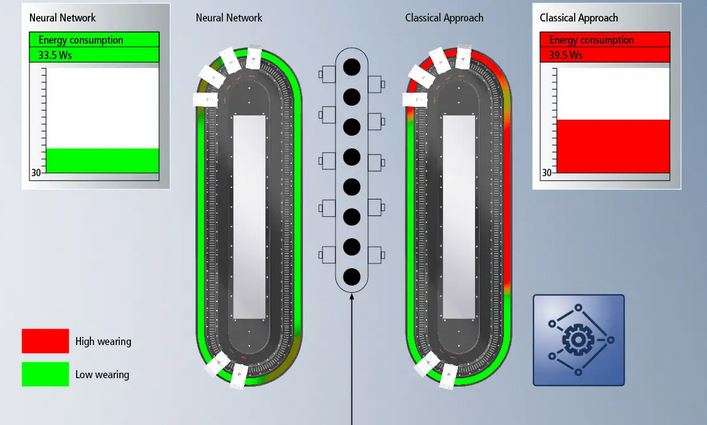
L'apprentissage automatique en tant que sous-domaine de l'intelligence artificielle fait de plus en plus d'avancées dans les technologies d'automatisation et de contrôle en apportant des avantages dans le développement de systèmes complexes. Au lieu de l'ingénierie classique, les techniques d'apprentissage en profondeur, telles que l'apprentissage automatique ou les réseaux de neurones, utilisent de vastes ensembles de données de processus. Des modèles créés et formés peuvent reconnaître des modèles et des lois à partir de ces données. Appliqué aux nouvelles données de processus, le modèle formé détecte les anomalies comme des pièces mal produites ou des changements dans la machine.
Un réseau de neurones
Les systèmes basés sur la connaissance, tels que l'apprentissage automatique ou les réseaux de neurones, offrent le principal avantage lorsqu'ils sont exécutés avec une capacité en temps réel dans les machines. Cela profite également aux applications exigeantes, telles que l'usure ou les applications de mouvement optimisées en énergie. Une machine d'inférence exécute le modèle dans le contrôleur et relie ces technologies à l'environnement de production classique.
Une grande variété de logiciels
Le flux de travail commence par les données, auxquelles plusieurs méthodes d'apprentissage automatique sont initialement appliquées pour identifier et former le modèle optimal. Une variété de bibliothèques de logiciels et de cadres (y compris Scikit-learn, PyTorch, TensorFlow, MATLAB ® , MXNet) sont disponibles pour cette partie de l'ingénierie. Le modèle formé est disponible dans un format d'échange tel que l'Open Neural Network Exchange (ONNX) pour le traitement avec des outils supplémentaires et pour l'exécution dans la machine d'inférence du contrôleur.
L'apprentissage automatique dans les contrôleurs capables de temps réel ouvre de nouveaux champs d'application, à savoir :
- La reconnaissance du comportement d'utilisation individuel d'une machine et l’adaptation des modèles de maintenance.
- L’optimisation de la consommation d'énergie et du comportement à l'usure des machines.
- L’évaluation des objets, des motifs et des structures dans les images de la caméra pour l'assurance qualité.
- La détection des anomalies de fonctionnement de la machine et l’identification des nouveaux états de fonctionnement.
- Le contrôle des processus difficiles à contrôler avec des algorithmes adaptatifs.
- L’amélioration de l'efficacité globale de l'équipement (OEE) avec des analyses de périphérie autonomes.
L’entreprise Beckhoff combine ces technologies innovantes avec une technologie de commande basée sur PC. En voici les caractéristiques :
- Le format d'échange ouvert ONNX permet un libre choix de l'outil de formation.
- La machine d'inférence est profondément intégrée dans l’exécution TwinCAT.
- Les exigences strictes en temps réel sont satisfaites à tout moment.
- Les fabricants de machines standard peuvent également fournir leurs applications d'apprentissage automatique à leurs clients dans un format de données binaire fermé (BML).
- Les reconfigurations, comme lors du changement de produits sur la machine, peuvent être effectuées avec un changement direct du modèle d'apprentissage automatique sans compiler ou redémarrer l’exécution TwinCAT.
- Toutes les données de processus peuvent être lues et écrites dans TwinCAT à partir du système d'E/S ou via un accès à la base de données.
Deux approches de l'apprentissage automatique
Les algorithmes sont les moteurs de l’apprentissage automatique. En général, deux principaux types d'algorithmes sont utilisés aujourd'hui : l'apprentissage supervisé et l'apprentissage non supervisé. La différence entre les deux se définit par la méthode employée pour traiter les données afin de faire des prédictions.
L’apprentissage automatique supervisé : ces algorithmes sont les plus couramment utilisés. Avec ce modèle, un expert en mégadonnées sert de guide et enseigne à l’algorithme les conclusions qu’il doit en tirer. Tout comme un enfant apprend à identifier les fruits en les mémorisant dans un imagier, en apprentissage supervisé, l’algorithme apprend grâce à un jeu de données déjà étiqueté et dont le résultat est prédéfini.
Comme exemples d’apprentissage automatique supervisé, on peut citer des algorithmes tels que la régression linéaire et logistique, la classification en plusieurs catégories ou les machines à vecteurs de support.
L’apprentissage automatique non supervisé : ce type de logiciel utilise une approche plus indépendante dans laquelle un ordinateur apprend à identifier des processus et des schémas complexes sans un guidage humain constant et rigoureux. L’apprentissage automatique non supervisé implique une formation basée sur des données sans étiquette ni résultat spécifique défini.
Pour poursuivre avec l’analogie de l’enseignement scolaire, l’apprentissage automatique non supervisé s’apparente à un enfant qui apprend à identifier un fruit en observant des couleurs et des motifs, plutôt qu’en mémorisant les noms avec l’aide d’un enseignant. L’enfant cherche des similitudes entre les images et les sépare en groupes, en attribuant à chaque groupe sa propre étiquette. Comme exemples d’algorithmes d’apprentissage automatique non supervisé, on peut citer la mise en groupes de k-moyennes, l’analyse de composants principaux et indépendants ou les règles d’association.
Choisir une approche
Quelle est l’approche la mieux adaptée à ses besoins ? Le choix entre un algorithme d’apprentissage automatique supervisé ou non supervisé dépend généralement de facteurs liés à la structure et au volume des données, ainsi que de l’utilisation à laquelle il est destiné. L’apprentissage automatique s’est développé dans un large éventail de secteurs, répondant à une variété d’objectifs métier et de cas d’utilisation, notamment :
- La valeur du cycle de vie des clients
- La détection d’une anomalie
- La tarification dynamique
- La maintenance prédictive
- La classification des images
- Les moteurs de recommandation
Et pour le futur ?
Cette technologie s’est beaucoup démocratisée pour les produits auprès des consommateurs, mais elle est encore relativement étrangère dans les applications industrielles, à l’exception de la reconnaissance d’image. La valeur ajoutée de cette technologie pour des machines industrielles standards n’est pas forcément « directe » dans le sens qu’une machine-outil n’a pas besoin de machine learning pour fonctionner, au contraire d’une application de vision. Il s’agit d’une optimisation de la machine (meilleures performances, meilleure maintenabilité). Cependant, ces optimisations peuvent rendre ces machines plus attractives et donc plus compétitives sur le marché.
A noter que les produits Beckhoff se retrouvent aussi dans l’automation des bâtiments. Le machine learning peut être utilisé dans ce milieu comme moyen de réduire la consommation d’énergie. C’est un sujet très actuel, et certaines écoles d’ingénieurs effectuent des recherches activement dessus.
Beckhoff Automation AG
CH-1400 Yverdon-les-Bains
Tél. +41 (0)24 447 27 00
La nomenclature de l'intelligence artificielle
L'intelligence artificielle étant un mot à la mode , il est sujet à de multiples interprétations. Afin d'établir une compréhension commune, divers termes relatifs à l'IA sont utilisés dans ce domaine.
- L'intelligence artificielle (IA) est l'intelligence dont font preuve les machines, celles-ci imitant les fonctions généralement associées à la cognition humaine. Les fonctions de l'IA comprennent tous les aspects de la perception, de l'apprentissage, de la représentation des connaissances, du raisonnement, de la planification et de la prise de décision. La capacité de ces fonctions à s'adapter à de nouveaux contextes, c'est-à-dire à des situations pour lesquelles un système d'IA n'a pas été formé auparavant, est un aspect qui différencie l'IA forte de l'IA faible. Dans ce rapport, nous ne ferons pas la distinction entre IA faible et IA forte pour des raisons de simplicité et parce que nous nous concentrons sur le contexte commercial.
- L'apprentissage machine ou Machine Learning (ML) décrit l'apprentissage automatique des propriétés implicites ou des règles sous-jacentes des données. Il s'agit d'un composant majeur pour la mise en œuvre de l'IA, car ses résultats sont utilisés comme base pour des recommandations, des décisions et des mécanismes de retour indépendants.
L'apprentissage automatique est une approche de la création de l'IA. Comme la plupart des systèmes d'IA sont aujourd'hui basés sur l'apprentissage automatique, les deux termes sont souvent utilisés de manière interchangeable, en particulier dans un contexte commercial.
- L'apprentissage automatique utilise la formation, c'est-à-dire un processus d'apprentissage et de raffinement, pour modifier un modèle du monde. L'objectif de l'apprentissage est d'optimiser les performances d'un algorithme sur une tâche spécifique, de manière à être en mesure d'atteindre ses objectifs.
L'objectif de l'apprentissage est d'optimiser la performance d'un algorithme sur une tâche spécifique, afin que la machine acquière une nouvelle capacité. Typiquement, de grandes quantités de données sont impliquées. Le processus d'utilisation de cette nouvelle capacité est appelé inférence. L'algorithme d'apprentissage automatique formé prédit les propriétés de données inédites.
- Il existe trois principaux types d'apprentissage dans la ML, à savoir l'apprentissage supervisé, l'apprentissage par renforcement et l'apprentissage non supervisé. Ils diffèrent par la manière dont le retour d'information est fourni. L'apprentissage supervisé utilise des données étiquetées (« la bonne réponse est donnée ») tandis que l'apprentissage non supervisé utilise des données non étiquetées (« aucune réponse n'est donnée »).
Dans l'apprentissage par réintégration, le retour d'information comprend la qualité de la sortie, mais pas la meilleure sortie possible. En pratique, cela signifie souvent qu'un agent tente continuellement de maximiser une récompense en fonction de son interaction avec son environnement.
- Depuis la fin des années 2000, l'apprentissage profond ou Deep Learning (DL) est l'approche la plus aboutie dans de nombreux domaines où l'apprentissage automatique est appliqué. Il peut être appliqué aux trois types d'apprentissage mentionnés ci-dessus. Les réseaux neuronaux dotés de nombreuses couches de nœuds et de grandes quantités de données constituent la base de l'apprentissage profond. Chaque couche ajoutée représente des connaissances ou des concepts à un niveau d'abstraction supérieur à celui de la couche précédente. L'apprentissage profond fonctionne bien pour de nombreuses tâches de reconnaissance des formes sans modification des algorithmes, pour autant que l'on dispose de suffisamment de données d'entraînement. Grâce à cela, ses utilisations sont remarquablement larges et vont de la reconnaissance visuelle des objets au jeu de société complexe « Go ».




